![]()
Fantasy football (FF) offers a great avenue for many data enthusiasts to apply their talents to a personal interest. It provides an intersection between a familiar domain, accessible data, and competition with friends. Additionally, success in fantasy football is such an inexact science, it feels like the perfect area where experimentation can give you the edge to hoist your league’s trophy.
Throughout my tenure as an FF General Manager, I’ve heavily used static reference sheets for my draft process, such as BeerSheets. These sheets provide projections on when (or for how much in auction drafts) a player should be drafted. There are two major issues with these sheets:
- They don’t take into account a critical aspect of any fantasy league - your opponents. Your opponents aren’t using the same strategy as your sheets. They may over value their hometown players. They may be passionate about certain bench players. Or, most likely, they may just be completely irrational. A sheet will not know these tendencies. Fortunately, we are approaching an era where we may be able to model these tendencies. Many FF leagues are approaching nearly a decade of running (or more). This equips us with a treasure trove of data on our opponents that can be used to our advantage.
- When a draft drastically deviates from the static settings of the sheet, your projections become less relevant. For example, if someone just drafted a player for $20 less than your projection, shouldn’t you be ready to spend more for the available talent?
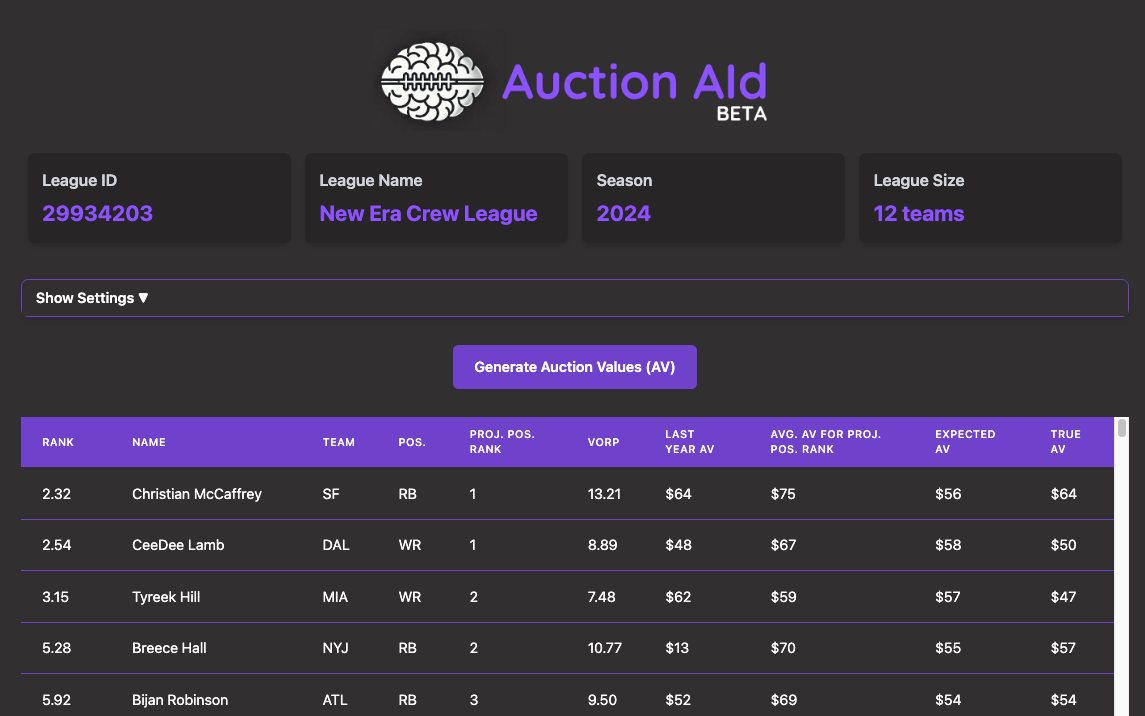
Thus, I started to work on Auction AId. The Fantasy Football draft tool that prioritizes league tendencies to provide real-time advice for auction drafts. First and foremost, this will be a tool developed for my own use, hence the focus on auction drafts, which is used by all of my leagues. In the future, it could be expanded for other use cases.
Before you get too excited, as of today, Auction AId only supports static projections using your league’s past data. Real-time support will be added prior to next year’s drafts.
Not interested in how the sausage was made? Feel free to quit reading and try out Auction AId here. If you care about the technical design, you can go to Key Design Decisions and Tradeoffs. If you are most interested in the Fantasy Football statistics that make Auction AId tick, jump to Auction AId Fantasy Football Analysis.
Value Objective
Auction AId will address several challenges currently seen in auction drafts:
- Gap in Auction Draft Tooling Support - most leagues use a snake draft format over auction drafts. I’d estimate less than 20% use the auction approach. This has led to a giant gap in tools that cater specifically to auction drafts.
- Opportunity to Leverage League-specific Data - most (if not all tools) leverage industry experts or cross-league data for their insights. This approach makes sense as most fantasy football player do not play in leagues that span many years. As leagues are starting to age, though, the data around league owner tendencies is starting to grow, which makes it ripe for insights.
- Dynamic Projection Updates - for the current available static tooling, the data you enter the draft with is the data you are stuck with. It does not react to the events of the draft. A dynamic tool that updates projected values based on the draft in real-time will add an additional advantage over other tools.
Requirements

Where possible, I try to avoid long lists. When it comes to requirements, a long list is unavoidable, so here we are! My favorite method of making long lists more digestible is trying to categorize and even sub-categorize the elements of a list, when needed. But, that doesn’t make it any more fun to read - feel free to scroll.
With that, the following lists and sub-lists capture the requirements that will need to be addressed by Auction AId. Please keep in mind, these requirements are specific to my personal use, since that is the main objective of the tool. Also, some of these requirements may seem superfluous. That’s because they are. I am intentionally over-engineering certain aspects of this project to provide myself exposure to additional technologies.
Lastly, this section only includes the requirements addressed at this time. Please refer to the “Next Steps” section for future requirements.
Functional Requirements Completed in Release 1.0
Data Management
- Able to ingest data from the following sources:
- ESPN Football API - player, league, etc.
- Industry Experts for projections, ranking, and past statistics
- FantasyPros
- E-mail Imports
- This is specific to my needs. My personal league had to do a redo a draft one year after some issues. The original draft results are only available in an ESPN generated summary e-mail… this feature will not be available in the public version (and not needed for most)
- Able to persist ingested data to mitigate data providers deleting historical data (as ESPN did for all league history prior to 2020)
- Able to persist 100% locally, or by integrating with AWS S3
Data Modeling Capabilities
- Leverage historical league data and expert projections to provide the following values for each player prior to the start of the draft:
- Expected Auction Value (EAV) - the predicted winning auction value of the player based on league tendencies
- True Auction Value (TAV) - the true value for a player based on historical performance and your ideal draft strategy
User Interface
- Provide a user interface to view the players and draft insights
Nonfunctional Requirements Completed in Release 1.0
Scalability
- Able to initialize leagues and conduct draft on multiple clients in parallel without issues
- After initial league data is scraped, subsequent runs of Auction AId run in <5 minutes
Reliability
- Zero fatal crashes during a draft during tests for my personal leagues
- Data validation should be completed on the data to ensure accurate models
Extensibility
- Support leagues hosted on the ESPN platform
- Support data available on the FantasyPros website
Authentication and Authorization
- Provide a secure implementation of loading data to S3
Cost and Ease of Use
- Can be run and used with very little to no cost
Project Overview
Auction Drafts 101
First, let’s cover ‘what is an auction draft’? The default type of fantasy football draft is a ‘snake’ draft, where each player takes turns selecting players. In these drafts, your initial draft position greatly determines who you are able to draft and, ultimately, how good your team might be (although, this is often debated).
An auction draft aims to remove the disparity between teams based on arbitrarily assigned draft positions by providing everyone the opportunity to draft each player… if you have the money. Each team starts with the same amount of money (e.g., $200 as a default) and the teams take turns ‘nominating’ a player. Bids are placed for the player, just like you would see at a real-life auction with an auctioneer. Once incoming higher bids cease, the team with the highest bid wins the player. If you have a player you love, then you can guarantee yourself you’ll get him, if you are willing to pay the price.

This type of draft opens up a whole world of different strategies. There is the opportunity to gamble on players you love, but the recipe for a winning team is clear: get the most value (i.e., points) across your players based on spending your full budget. Auction AId aims to help you find this value by finding the players and positions where your league over or under pays to allow you to find where the value is.
Auction AId High-level Architecture

The Auction AId tool uses a slight modification of the FARM tech stack, which consists of FastAPI, React, and MongoDB.
For our needs, MongoDB was replaced with AWS S3 object storage. As an open-source, user run tool, I wanted to pick a cloud storage option with a low barrier of entry for users to persist their data off their local machine. AWS S3 is very easy to create, configure, and use, so it seemed like a solid choice at this time. Additionally, Auction AId allows for a ‘local only’ mode to save data directly to the computer running the program, which is even easier for most users.
In the next two sections, I’ll discuss other key design decisions and provide implementation details of the critical components.
Key Design Decisions and Tradeoffs
Frontend
The frontend needed to offer three primary characteristics:
- Customizability - while the Release 1.0 of Auction AId is simple, there is a long backlog of features I’d like to implement. With that, I wanted to find a frontend stack that I could use for the long haul without refactoring in the future.
- Performance - once real-time draft updates are implemented, the UI will be updating after each draft pick. A delay in the UI could result in missing on an important draft opportunity. The UI must support means of improving performance.
- Python Integration - I am most comfortable developing in Python, so it was the clear choice of the backend. Thus, I need a front end that will work well with Python.

During my research, I came across four top candidates: Streamlit, Django, React, and Next.js. Streamlit and Django seemed like they will be a great fit for some more light-weight projects, but didn’t offer the customizability I need for Auction AId long-term.
The decision between React and Next.js was not as clear. In the end, I selected React since it seemed like a good starting point to better understand the world of Javascript frameworks. Next.js is built on top of React, so I wanted to build a fundamental understanding of React before diving into another level of abstraction.
In the future, I’ll consider Next.js more deeply since it seems to offer better performance and Search Engine Optimization (SEO).
Application Programming Interface (API)
The same design tradeoffs were considered for the framework selected to build the APIs in Auction AId.

While express.js is often used with React, it is a JavaScript framework, which didn’t meet my Python needs.
Similar to Streamlit and Django, Flask seemed like a great light-weight option, but didn’t offer the type of robust performance I want long-term.
Finally, I decided on FastAPI, which offers strong performance as well as data validation through Pydantic. It integrates well with React using the axios package. With a technical stack in hand, we can bring Auction AId to life!
Implementation Deep-dives
Raw Data Model

The raw data model from the input sources are composed of custom Python objects as designed by cwendt94 and his espn-api, along with dictionaries produced from Auction AId’s web scraping processes. The key pieces of data include:
- League Objects - contain the data a single year of a league, including all fantasy teams, the players on those teams, the results of the draft, and much more. For full details, see here.
- FantasyPros Expert Projections - various metrics, which aim to predict the value or draft position of a player, prior to the season. These projections are used by many Fantasy players to assist with their draft plans and can be configured based on your league size or scoring format. Additionally, FantasyPros has data for some of these areas dating back to 2013, these allow for even more data to train Auction AId. These include:
- Expert Consensus Rankings (ECR) - an average ranking for a player by taking into account hundreds of expert’s rankings
- Value Based Drafting Value (VBD) - a numeric value assigned to a player to capture what value that player brings to a fantasy team. We will discuss this in much more detail later on, as this is how we can determine how much a player is worth in an auction draft!
- Average Draft Positions (ADP) - the average draft position in a snake draft for each player, based on actual drafts across various fantasy platforms
- FantasyPros’ Auction Value Projection - how much FantasyPros believes a player is worth
Each individual input source is saved to either S3 or local storage to make the data more accessible after the initial run, thus improving the run-time performance.
JSON Serializing for Object Storage
The introduction of a persistence layer brings about some new technical requirements. The data types used in-memory during a piece of code’s execution (i.e., our Python dictionaries and custom object) cannot be sent to storage as-is. Thus, we need to prepare the data for storage through the process of Data Serialization.
In Auction AId’s Python code, data serialization is completed using two methods:
Using Built-in Python json package
This process is so common that Python has a built-in package to take data and write / read to JSON using json.dump / json.dumps and json.load / json.loads.
The s at the end was very confusing to me until I had an a-ha moment… the s is not there to mean multiple… it stands for string! Those methods just create a JSON string, while the others involve a JSON file to be written / read. Let me demonstrate creating a JSON string:
# A dictionary of dictionaries
player_projections_dict = {'adp':
{"Evan McPherson": {"pos": "K",
"projected_pos_rank": 8, "adp_avg": 181.0},
"Geno Smith": {"pos": "QB",
"projected_pos_rank": 24, "adp_avg": 182.0},
"Isaiah Likely": {"pos": "TE", "projected_pos_rank": 19,
"adp_avg": 186.5}
},
'vbd':
{"Evan McPherson": {"vbd": 0,
"vorp": 0, "vols": 0},
"Geno Smith": {"vbd": -13,
"vorp": -13, "vols": -31},
"Isaiah Likely": {"vbd": -7,
"vorp": -7, "vols": -25}
}
}
# Create a JSON string
player_projections_json_string = json.dumps(player_projections_dict)
# Compare the data types
print(type(player_projections_dict))
# <class 'dict'>
print(type(player_projections_json_string))
# <class 'str'>
Here, a Python dictionary is created and then turned into a JSON string using the json.dumps method. This JSON string is serialized and able to be sent to storage. For example, the JSON string can be sent to S3 using the boto3 package:
import boto3
s3_conn = boto3.client('s3',
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
region_name=region_name
s3_conn.put_object(Bucket=self.bucket_name, Key=object_key,
Body=player_projections_json_string)
```
If you'd like to handle the process of creating the JSON string and placing it on a file in a single operation, you can use the `json.dump()` method:
```python
# Create a file path for storing the JSON
appdata_path = os.path.join(os.getcwd(), "backend/AppData/league")
file_path = os.path.join(appdata_path, object_name)
with open(file_path, 'w') as f:
json.dump(player_projections_dict, f, indent=4)In this code, we never directly create or have access to a JSON string. The dictionary is passed into the json.dump() method and saved directly to the created file path.
The json.load() and json.loads() methods operate just like the above, but just in an opposite fashion for reading JSON files or JSON strings.
This approach works great for simple data structures, like arrays and dictionaries, but can struggle when it comes to complex data types. A complex structure like the custom League object in Auction AId has relationships between the elements in the data that may not be captured correctly with the general serialization approach offered in the json package. For example, the deep relationship between a team, a player, and a draft pick.

These complex relationships and the details of their corresponding custom Python classes can be lost when serializing and deserializing data. To address these issues, you can create custom encoding / decoding functions to instruct the json package how to handle these complexities, or you can use another package which is able to infer relationships in more complex data types.
Using jsonpickle package
The jsonpickle package is a:
Python library for serialization and deserialization of complex Python objects to and from JSON. The standard Python libraries for encoding Python into JSON, such as the stdlib’s json and simplejson can only handle Python primitives that have a direct JSON equivalent (e.g. dicts, lists, strings, ints, etc.). jsonpickle builds on top of these libraries and allows more complex data structures to be serialized to JSON. jsonpickle is highly configurable and extendable–allowing the user to choose the JSON backend and add additional backends.
In other words, it expands on the json package to handle objects just like Auction AId’s League object. There are many different parameters you can configure to make sure the data is serialized properly. For Auction AId, the implementation is as follows:
from espn_api.football import League #https://github.com/cwendt94/espn-api
import jsonpickle
league = League(league_id=league_id, year=year, espn_s2=espn_s2, swid=swid)
league_json = jsonpickle.encode(league, max_depth=30, separators=(',', ': '))The max_depth parameter tells jsonpickle to keep diving deeper into the relationships of the League object to make sure all the data is properly serialized. The result is a JSON string ready to be uploaded to S3 that will be successfully deserialized into the original custom Python object using jsonpickle.decode().
Auction AId Fantasy Football Analysis
The premise of Auction AId’s approach to a Fantasy Football draft is that a league will overvalue certain players and positions. If we can determine what your league expects a player’s value to be and compare it to a true value of the player, then we can identify the overlooked players that will bring your team the most value for the minimum cost.
To do so, we’ll need an approach for defining Expected Auction Value (EAV) and True Auction Value (TAV).

Determining True Auction Value (TAV)
I consider myself to be a lot like Brad Pitt… not in terms of looks or talent, but in the sense that we both pretend to know a lot about sports statistics. That’s right - I’m talking about Moneyball! The concept of assigning a numerical value to a player has been around for a long time, especially in baseball.
There are many approaches on how to apply the Moneyball concepts to Fantasy Football. First, we should align on some key concepts. Then, we can discuss how they are applied to create a mathematical approach to determining a player’s value.
Before diving too deep, I must give a shoutout to this post, which served as the foundation for Auction AId’s approach for TAV. Where ever you are, azmat, thank you for the inspiration!
Key Concepts for TAV
Value Based Drafting - a single numeric value that takes into account the value of a player compared to other similar players (i.e. positions). Instead of the best overall player, you draft the player that adds more value compared to what your opponents will have.
If you are already spending large amounts on an RB in your auction drafts, then you’re already lowkey using VBD. We know that a QB scores the most fantasy points throughout the season, but we know a RB is more valuable because the elite RBs significantly outperform other RBs. Thus, we are willing to spend more on a RB. This concept of relative performance, compared to other players at the same position, brings us to the next key concept.
Value Over Replacement Player (VORP) - this is the exact same concept that is used in Moneyball. It is a single value that represents a player’s value relative to a ‘baseline’ player at the same position. This value allows us to compare if the top RB should have more value than the top QB. If the top QB has a low VORP, it means that the gap between this ‘expensive’ QB and an ‘average’ QB may not be worth the associated cost. The basic formula for VORP is:

- Player Output - is the statistic by which you want to measure a player’s ‘production’. In Auction AId, this can be a player’s point-per-game (PPG) or total points. PPG would help account for injured players, but may result in over-inflating some player value if they only played in one very successful game.
- Replacement Player Output - the player output of the player determined to be a ‘replacement’ player. There are various strategies for determining a replacement player, and Auction AId currently supports two. Additional approaches are under consideration and listed in the Next Steps section:
- First $1 Player Drafted - this approach basically defines a replacement player based on how your league actually values players during the draft. Auction AId will average the historical auction values of players and use this average to determine at which point your team thinks players are worth only $1. This is illustrated later in the blog post.
- Last Starter - this is a simple approach that determines the lowest ranked player to start in your league is the replacement player. If you have 12 teams each with 1 QB, then the 12th QB based on PPG or total points will be the replacement player.
Many people use projected player outputs to calculate VORP, but Auction AId uses real past data to determine a value that reflects actual league results.
Calculating Value Over Replacement Player (VORP)
Let’s take a look at Auction AId calculating VORP for one of my leagues using PPG as the Player Output and ‘First $1 Player Drafted’ as the replacement player. Using the actual fantasy results for my league, each QB is ranked by PPG. In the table below, the PPG for the best QB over the years is 24.7525.
At the same time, the actual average auction value of the player is also calculated. As an aside, look at how hard it is to predict even the best QB! The best QB on average costs $10.25. This shows how even a ‘cheap’ player can end up a great performer at this position.
Anyways, the first $1 or less player is QB10, so this is our replacement player! The PPG of the replacement player is subtracted from each player and we now have VORP!
| position | Average PPG | Average Auction Value | Replacement PPG | VORP |
|---|---|---|---|---|
| QB,1 | 24.7525 | 10.25 | 19.5475 | 5.205 |
| QB,2 | 23.4875 | 6.5 | 19.5475 | 3.94 |
| QB,3 | 23.055 | 20.25 | 19.5475 | 3.5075 |
| QB,4 | 22.0675 | 6.75 | 19.5475 | 2.52 |
| QB,5 | 21.545 | 8 | 19.5475 | 1.9975 |
| QB,6 | 20.745 | 7.75 | 19.5475 | 1.1975 |
| QB,7 | 20.215 | 6.5 | 19.5475 | 0.6675 |
| QB,8 | 19.81 | 14.75 | 19.5475 | 0.2625 |
| QB,9 | 19.68 | 14 | 19.5475 | 0.1325 |
| QB,10 | 19.5475 | 0.25 | 19.5475 | 0 |
| QB,11 | 19.235 | 0.5 | 19.5475 | 0 |
| QB,12 | 18.905 | 3.5 | 19.5475 | 0 |
Great! But, that’s not an Auction Value…
You’re right. Now, we must convert this VORP into an auction value. Follow me here…
click to zoom

The trick is to have a process that takes into account the output of the player, the scarcity of the position, and the make up of the roster to ensure money is spent in a way that maximizes a team’s overall value. I don’t think I can improve on the explanation beyond the above pictorial representation, but this approach takes into account each of the areas I mentioned - all using your real league data!
Auction AId’s approach to TAV will likely evolve over time. If you have any feedback on improvements, please reach out to let me know!
Determining Expected Auction Value (EAV)
While TAV is all about the reality that occurred, Expected Auction Value (EAV) is all about what people think will happen and how your league reacts to that information. Of course, predicting human behavior is difficult. We’ll tackle this problem using some of the data science knowledge I picked up when getting my Online Master’s of Science in Analysis from Georgia Tech (Projects While Completing Master’s of Science in Analytics at Georgia Tech).

Auction AId completes all of the crucial steps to create and prepare data for modeling, but we’ll focus on the final step so we can take a deeper look at the results.
To determine what a Fantasy Manager may do at draft time we need the model to have the same information that a person would have at that moment in time. This means, our features should reflect the FantasyPros’ projection for a player at draft time and what the league determined that player’s value was. Luckily, the data sources ingested include past FantasyPros projections dating back to 2013.
The data should not include the real results of the season for which the teams are drafting - that’s the data relevant for our True Auction Value (TAV). With this in mind, the following features were fed into the model. The model also scores the feature importance for determining the EAV, which is included in this table.
| Feature | Description | Importance |
|---|---|---|
| Average Auction Value for Projected Position Rank | The average value the league pays for a player based on their projected ranking. For example, the top projected WR (i.e., WR1) may go for $62 on average. | 0.80 |
| Projected Position Rank | The projected position rank of a player based on FantasyPros projections. | 0.09 |
| Projected VBD | The FantasyPros projected value of a player | 0.03 |
| VBD to Auction Value Ratio | The ratio of VBD to the auction value of the player in the league. This feature attempts to quantify players that are historically overvalued or undervalued by a league. | 0.02 |
| Average Points-per-Game (PPG) | The average PPG of the player in the league | 0.02 |
| Previous Year Auction Value | The AV of the player in the previous year’s draft | 0.01 |
| Position Encodings | The position of the player. | <0.01 |
| No surprise, the league’s reaction to the projected rankings of a player is the strongest indicator on the player’s EAV. |
Using Random Forest Models to Predict EAV
Two supervised models were considered for determining EAV: Logistic Regression (LR) and Random Forest (RF). The results of RF significantly outperformed logistic regression across the evaluation metrics of R^2, Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE). This is not unexpected. It is common for RF to offer better performance, but it comes at the cost of interpretability. In other words, it is more difficult to see why the model performs well. In the business world, when you are convincing stakeholders to trust your model, this can be a huge problem. In Auction AId, we are here to win at all costs - so, we just go with the best performing model.
![[Random Forest#Description]]
![[Random Forest#Underlying Mechanics]]
To get the best result possible, Auction AId tunes the hyperparameters used in the model during each run.
# Define hyperparameter for Random Forest Model
param_dist = {'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4],
'bootstrap': [True, False]
}
# Initialize base model
base_model = RandomForestRegressor(random_state=42)
# Initialize RandomizedSearchCV for cross-validation of hyperparameter tuning
model = RandomizedSearchCV(
estimator=base_model,
param_distributions=param_dist,
n_iter=25,
cv=5,
verbose=1,
random_state=42,
n_jobs=-1,
scoring='neg_mean_squared_error'
)
best_model = model.best_estimator_ ![[Random Forest#Hyperparameters]]
When Auction AId ran on my personal league, the best model used 100 estimators, 5 minimum samples for a split, 2 minimum samples for a leaf, a max depth of 20, and bootstrapping set to true. This model had these results:
| Evaluation Metric | Dataset | Value |
|---|---|---|
| R^2 | Training | 0.94 |
| R^2 | Testing | 0.80 |
| Root Mean Squared Error (RMSE) | Training | $3.60 |
| Root Mean Squared Error (RMSE) | Testing | $5.41 |
| Mean Absolute Error (MAE) | Training | $1.66 |
| Mean Absolute Error (MAE) | Testing | $2.46 |
These are pretty solid results, which should give a decent look into how a league will value a player. Of course, auction draft strategies change over time, which means using old data may not predict what is the current thought of the league. Over time, though, more data should make the predictions of EAV more and more dependable.
Key Results
Release 1.0 provides a really exciting starting point for tackling fantasy drafts using your past league data. While there is always room for improvement on the calculation of TAV and EAV, the historical auction values calculated and displayed at least provides a reference point that can prevent you from overpaying on players.
During the development quite a few valuable lessons were learned that will be addressed in future projects. A couple of these lessons include:
- Detailed Design of APIs Prior to Significant Development - I did create a high-level design of Auction AId, but did not list out the specific inputs and outputs to API calls. Since I didn’t define enough detail up front, there were quite a few cases where I needed to refactor code to get the proper data in the proper format for various functions. This did add some time to development, which I believe could have been avoided with some more design work at the beginning. This will be especially important during Release 2.0 development, which Auction AId starts to handle real-time updates.
- Domain Knowledge Cannot Be Undervalued - while development did take a large amount of time, one of the most time-consuming parts of creating Auction AId was researching and understanding advanced Fantasy Football projection metrics, like VBD, Replacement Player, etc. The importance of domain knowledge has always been evident in my career, and this experience just emphasized that point.
Next Steps
I am not planning on quitting Fantasy Football anytime soon, so I have a long horizon for implementing new features into Auction AId. In an attempt to prevent myself from boiling the ocean, I am tracking future features across several releases. If you have any recommendations, please feel free to let me know!
AuctionAId 2.0
- Frontend
- Redo workflow to start with central league overview / history home page
- Update UI to grey out non-auction and older league years out if data is not available from ESPN
- Increase test coverage on cases of excluding seasons
- Update UI to grey out non-auction and older league years out if data is not available from ESPN
- Implement real-time draft updates and update frontend to easily identify currently nominated player
- Determine approach for notifying if the nominated player is one that should be targeted by the users that also considers the user’s current drafted roster
- Redo workflow to start with central league overview / history home page
- User Authentication and Authorization
- Allow for user to create an account for Auction AId via Google account
- Allow for user to load league setting through an ESPN log-in with cookies
- Models for Expected Auction Value (EAV)
- Explore additional features to improve model performance:
- Player Name
- Would love to do this catch the tendencies of people to fall in love with players, but would result in too many features.In the future for more advanced models, could explore Keras embeddings
- League Setting, such as: Team Composition (i.e., number of QBs, RBs, etc.), Scoring settings
- I believe this is essentially captured in the past auction values, but it wouldn’t hurt to experiment
- Features that may impact EAV in Real-time:
- Owner roster needs
- Remaining auction budgets
- Current draft Auction Values
- Player Name
- Explore additional features to improve model performance:
- Statistical Analysis for True Auction Value (TAV)
- Technical Updates / Refactoring to Host as Web Application
- Reconsider S3 usage compared to other potential stores based on cost; S3 free tier supports:
-5 GB of Standard Storage
- 20,000 Get Requests
- 2,000 Put Requests
- Reconsider S3 usage compared to other potential stores based on cost; S3 free tier supports:
-5 GB of Standard Storage
AuctionAId 3.0
- Expand to additional Fantasy Football platforms, such as Sleeper, Yahoo, NFL, etc.
- Implement the ability to input keepers and their associated values prior to generating the Auction AId
- Update UI to allow for for increment / decrement for Auction Dollars per Team and Keepers
- Consider the impacts to TAV and EAV -Auction Value Strategy | Fantasy Football - Footballguys Forums
“To adjust for keepers I keep a separate spreadsheet that is linked to my auction sheet that tracks the keepers and subtracts the dollar amount kept for those players from the remaining auction dollars left to use. I also subtract the players from the projection sheets that are kept and their corresponding projections thus the VORP stays true. Doing this gets me a cost per point, which I then turn into an auction value and compare data for the positions. It’s been scary accurate over the last five or six years and I’ve been pretty good at being able to predict what the 13th running back off the board will go for (or 5th or 11th, etc etc). And while there are certainly outliers as auctions are unpredictable and people fall in love with players for different reasons, the averages across the spectrum give me a massive advantage over my league mates imo (I’ve won 6 league titles in the past 10yrs since I started incorporating this method).”
- Explore approaches for improve calculation of True Auction Value (TAV) via statistical analysis: -Add alternatives for defining the replacement player used in VORP, including: - Best Average Player - Baseline Player Strategies - Based on ‘Game Starts’, rather than season stats - 2023 Value-Based Draft Baselines : r/fantasyfootball - Simiarl approach, but using an Exponential Moving Average (EMA)
AuctionAId 4.0+
- Support TAV and EAV calculations for Free Agent Acquisition FAAB for in-season waivers
- Support TAV and EAV calculations for [trade proposals]( VORP and VOBP and how it can help you value players : r/fantasyfootball)
- Use a VORT calculation for TAV, rather than VORP!
Tags
#blog-post #technical-project